This post introduces my highlights on ICLR 2016 submssions. They are as listed:
- Stacked What-Where Auto-encoders1
- Neural Variational Inference For Text Processing2
- Reasoning in Vector Space: An Exploratory Study of Question Answering3
- Infinite Dimensional Word Embeddings4
- Towards Universal Paraphrastic Sentence Embeddings5
- Generating Images From Captions With Attention6
- Visualizing and Understanding Recurrent Networks7
- Generating Sentences From a Continuous Spaces8
- Alternative Structures For Character-Level RNNs9
Stacked What-Where Auto-encoders
This work is from NYU group, led by professor Yan LeCun. It aims at improving the encoder-decoder architecture in CNN, very similar to that in Seq2Seq learning. As Yan’s style, this paper is full of intuition, such as the reason why the choose certain regularizers.
The proposed architecture is illustrated in the right of Figure 1. Specifically, Stacked What-Where Auto-Encoders (SWWAE) is based on feedforward Convnet and Deconvnet. The “what”, for the max function, is the content and position features of max-pooling layers which are then passed to next layers. Meanwhile, “where”, for the argmax function, is the location information of max-pooling layers, which are used to inform decoder in parallel. Therefore, the combination of “what” and “where” can guide the decoder reconstruction when unpooling.
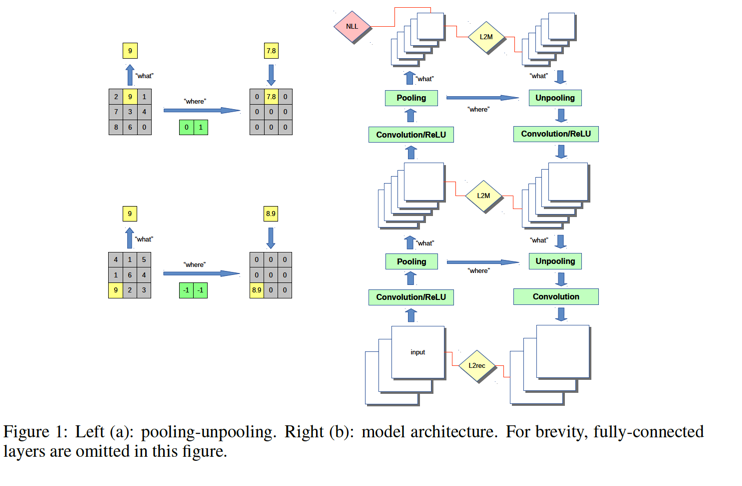
In order to faciliate the “what” and “where”, three losses are designed for the networks as in Equation 1: discriminate loss, input-level reconstruction loss for “what” and intermediate-level reconstruction loss for “where”.
As said before, this paper is intuitive, especially in Section 3. The authors first explain why it is beneficial to use the soft version of max/argmax functions for “what” and “where”; then, they discuss the reason for a hybrid loss function. Of course it is because of generalization and robustness; lastly, they emphasize the importance of intermediate loss for together learning “what” and “where”.
 The experimental results show that figures generated by SWWAE are clearer and cleaner.
The experimental results show that figures generated by SWWAE are clearer and cleaner.
Neural Variational Inference For Text Processing
This work proposes a novel generative neural variational framework and extends two models for two NLP tasks based on their framework. The two tasks are unsupervised document modeling and supervised question answering (selection). By applying to these two different tasks, the authors demonstrate the generalization and efficiency of their generative neural variational framework.
The key to this framework is \(h\) as latent semantics. For document modeling, they proposes the model called Neural Variational Document Model (NVDM) where \(h\) is for latent document semantics. For question answering (selection), the model is called Neural Answer Selection Model (NASM) where \(h\) is for latent question semantics. In NVDM, the stochastic generative model acts like a variational autoencoder in the unsupervised settings. And \(h\) is directly generated by the prior \(p(h)\). On the contrary, in NASM, \(h\) is generated by \(p(h|q)\) in the supervised fashion.
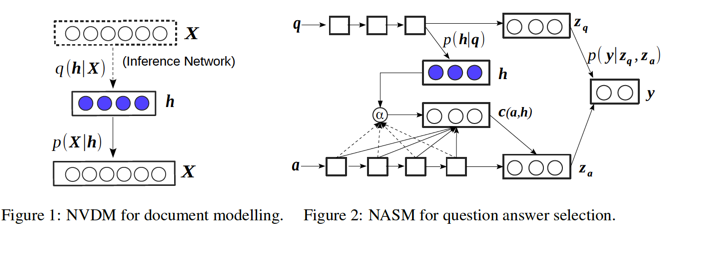
The experimental results are promising. NVDM performs outstanding and superior to all compared discrete generative latent models, which demonstrates that continuous(stochastic)latent models are better in their expressiveness and generalization. Similarly, NASM outperforms others in question answering task, showing that stochastic latent variable are good at modeling question semantics.
At last, the authors emphasize the three advantages of their framework: (1) Simple and effective; (2) Generalized for both unsupervised and supervised; (3) Can be applied to all existing neural networks, e.g. CNN and LSTM.
Reasoning in Vector Space: An Exploratory Study of Question Answering
This work is from Microsoft, which can be treated as a detailed analysis for Facebook 20 AI tasks (FB20). As claimed in the paper, existing work on FB20 is end-to-end which is deficient in analyzing the error-case and thus finding direction to improve. It is ambiguous whether the error is caused by semantic modeling or by reasoning process. To this end, this work “dimantles” the process of end-to-end reasoning by using tensor product representation (TPR) associated with common-sense inference, resulting in a almost perfect performance on FB20.
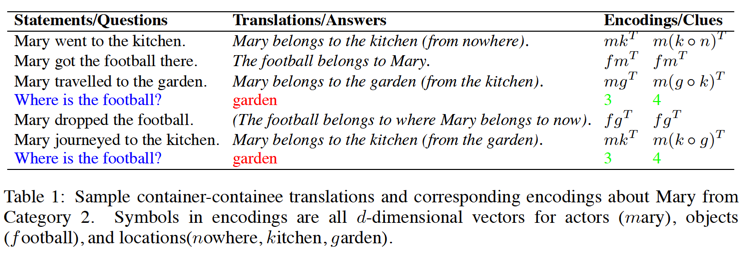
The paper is easy to read. My concern are: (1) the common-sense inference, e.g. west is the opposite of east, might limit the scalability of this work. It is just like a knowledge base, which is now customized for FB20, but far from real world problems; (2) TPR is good at reasoning, but might be deficient in representation.
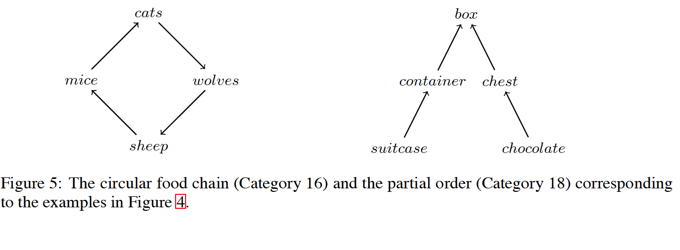
Infinite Dimensional Word Embeddings
Word embeddings generated by existing approaches are all fix-sized vectors. However, the semantic information capacities (like complexity) of words are indeed varied. Polysemy words that have rich meanings, such as net (web net, or fishing net) are more complex than those with only one specific meaning. The formers have larger semantic capacity and thus should have larger complexity. Motivated by such observation, this work assumes that vectors of polysemy words should be longer.
similar ideas can be found in previous work. For example, the ICLR’15 work of Gaussian Embedding10 incorporates the complexity of words by using the convariances of Gaussian distributions. It is further extended by a recent work11 to mixture Gaussian embeddings which aims at modeling word polysemy. Another line of research, e.g. NIPS’14 work from Ryan Kiros, enlarges the capacity of embeddings by incorporating meta-data information into tensor representations.
Different from these variations, this work proposes infinite Skip-Gram (iSG), which : (1) embeds words by jointly modeling w(word), c(context) and z(dimension) as a joint Gibbs distribution. Following infinite RBM, iSG is able to generate word embeddings whose dimension sizes are data-dependent and thus no longer fixed; (2) iSG’s parameter space does not expand. (3) which means iSG’s capacity is as same. The experiments show that when using full context, the nearest neighbouring words (NNW) generated by iSG are more specific and concrete.
However, my concern is that, how to apply such embedding variant to longer semantic units? For example, how to compose sentences from different-sized word vectors? A similarity score between words is not enough. We need go beyond words.
Another awesome note is here.
Towards Universal Paraphrastic Sentence Embeddings
This work focuses on sentence-level distributed representation, especially general and universal representation instead of domain- or task-specific ones.
The idea is straightforward. They utilize external semantic resource, Paragraph Database which contains large amounts of phrase pairs and can be used to design objective function: the cosine similarity of embeddings from similar phrases should be higher. After learning word embeddings, this work tries two kinds of models for composition to sentence: averaging embeddings (and their variants) and LSTMs. I find it similar of the first kind of model to ACL’15 work Deep Averaging Network (DAN)12.
The results are very interesting. Among the 20 tasks, the simplest averaging vector model outperforms others with a large margin. The silver medal is won by averaging vector + projection. And LSTMs lag behind. The results are at the first glance astonishing. But it is reasonable because they are based on domain independent tasks.
Generating Images From Captions With Attention
This paper extends and combines two generative neural network models: one is the previous-introduced DRAW with differential soft attention mechanism13; the other one is the deterministic Laplacian pyramid adversarial network14 for post-processing. Upon these, the novelty of this work is to reverse “classic” image captioning, which is image->caption, to image generation, as caption->image.
Concretely,
First, they extend the DRAW model to be conditional when generating, so that it adapts to a conditional generative model, namely alignDRAW. See the upper right part of Figure 2 in their paper, \(p(x|y, Z_{1:T})\)。Such conditional extension is important for performance. As what they said,

Second, they combine alignDRAW with GAN4 to take place of the inference part. And further sharpen units are added to reduce blurrness of the images (scences). Note that the “sharpen” units are nothing to do with semantic understanding or altering. Rather, they simply function as literally “sharpen”.
Third and maybe the most important, it is relatively difficult to generate images from captions. To tackle this, the authors follow the hints from the attention mechanism, that is, when attention is imposing on “strong” words in the captions, there will be corrosponding clear objects in the image; on the contrary, the object won’t show up if its attention “fails”. This intuition is verified and specified in the experiments by substituting image elements (not only objects), which further demonstrates the advantages of their conditional alignDRAW. One advantage, for example, is its generalization. Their alignDRAW, in this work, can generate images with objects which have never been shown in training data.
Yet the success of generalization, the caption->image generation is difficult as said before. Although Deep Learning has proven effective in image object recognition (such as ImageNet task), to discriminate dog vs. cat seems too be hard under multi-modal settings. It cannot only be attributed to the complication of image generation, but also the complex of multi-modal framework, e.g., the integration of differential and deterministic networks.
Anyway, this paper is clear and easy followed. Anyone who is unfamiliar with attention model, nor with image caption generation, can get started with it and enjoy their odyssey.
Multimodal linguistic regularities
One more step, I want to slide to one attractive slide, in the talk from Professor Ruslan Salakhutdinov, that is, Multimodal linguistic regularities. Remember the tipping point of word2vec, king - man + woman = queen? That is a kind of linguistic regularities. So, multimodal linguistic regularity will be something like this:

Using the intuition in the alignDRAW work, there comes a naive approach to implement such multimodal linguistic regularity. Just replace the word(s) in the caption with strong attention(s), in subject to little change in the attention(s), the \(\alpha\)(s), and then we can get the “customized” linguistic regularity perseving image. Let’s see one “customized” service, the color:

As color is the fundamental and thus “simple” element in image task, it is expected to see more interesting “customized” service. So, how about these?

All these slides come from Ryan Kiros, one student of Professor Ruslan Salakhutdinov and in his share at CIFAR Neural Computation and Adaptive Perception Summer School 20145.
Note that attention is only a naive way, maybe too naive, to implement the multimodal linguistic regularities. To become more powerful and general, one need, at least, to understand the structures/relations between objects, which remain open!
Visualizing and Understanding Recurrent Networks
This work is an exntension of the famous blog, «The Unreasonable Effectiveness Of RNN» from Andrej Karpathy.
Through controlled experiments, the work is aimed at quantatively why char-LSTM is powerful and basically, is it really able to model the often cited long term dependency? Like what is revealed in the the post by Yoav Goldberg, this work claims, the astonishing cability of char-LSTM is, yes, the log term memory, which is presented by the pairing of brackets, quotes in this work.
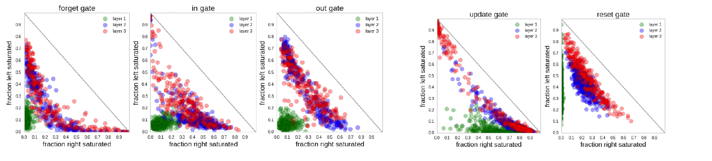
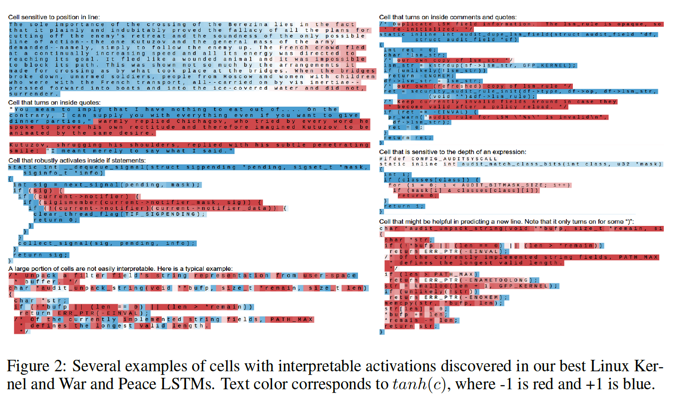 Additionally, by using visulization techniques, this work analizes the gate activation statistics and error types. The authors conclude that certain cells in char-LSTM are in charge of certain character position, demonstrating its long term memory modeling capacity in the mechanism level. The error case analysis, also proves it by reducing the errors in handling long distance information, e.g. bracket and quote.
Additionally, by using visulization techniques, this work analizes the gate activation statistics and error types. The authors conclude that certain cells in char-LSTM are in charge of certain character position, demonstrating its long term memory modeling capacity in the mechanism level. The error case analysis, also proves it by reducing the errors in handling long distance information, e.g. bracket and quote.
Generating Sentences From a Continuous Spaces
I like this work very much. The second author of this work previously published a pioneering work, Gaussian embedding, in ICLR 201513. After reading both these two work, I don’t know which comes first, becasue the intuitions behind this two work are very similar.
To start with, the authors observe that the vanilla LSTM decomposes steps to prediction outputs, lacking of continuous global information, which will harms the coherence between the generated sequences. For example, the length of sentences, the part-of-speech information or the topic, can be very informative for coherence. To incorporate the global representation of sentence features, the author applies the Variational Autoencoder into RNNLM, and thus implementing a generative RNNLM with global continuous information transition.
Compared to unsupevised Sequence Autoencoder and Skip-Thought Vectors, the Variational Autoencoder RNNLM uses a posterior recognition model associated with a latent variable, \(z\), to take place of the encoder in the vanilla RNNLM. Therefore, the encoder no longer learns point-based likelihood. Rather, the distribution-based likelihood. This intuition is similar in Gaussian embedding, which learns distribution-based embeddings for words. This is the key to the coherence perserving in sentence sequences.
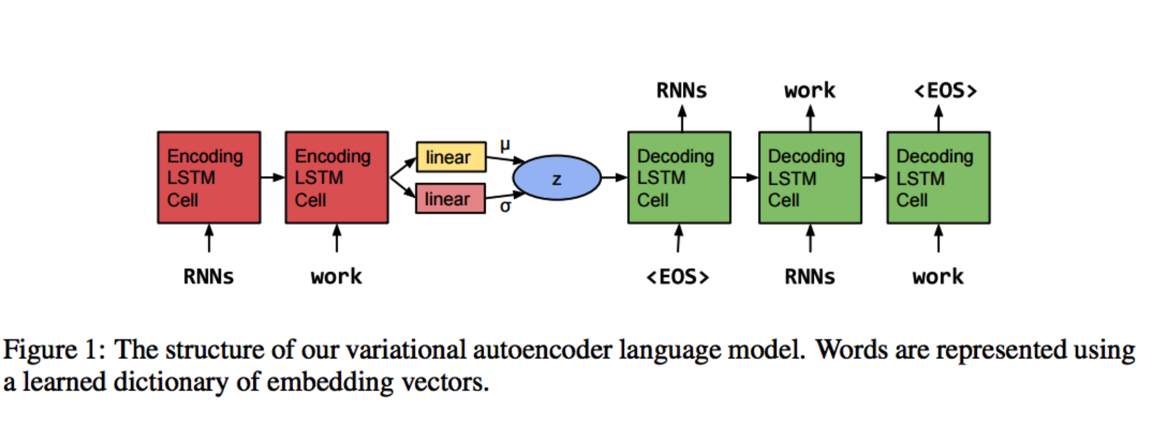
Note that this work is the first to apply the homopoly concept on sentences, as claimed in the qualitative results part in their paper. They use this concept to explore the intermediate sentences generated by the intermediate states (codes) in autoencoder. And they conclude that, they keep grammar and coherence (smooth topic transition) among these intermediate sentences. Very intuitive and interesting result.

This work also applies highway networks in the experiments.
Alternative Structures For Character-Level RNNs
The following two papers I want to mention motivate from the information flow improvment between encoder and decoder. The first work, is done by Facebook AI Team.
Although char-RNN is considered beneficial for modeling subword information, it has less input/output parameters according to the smaller vocabulary size. Thus, the only way to improve its capacity is to deepen and widen the hidden layers, resulting in overfitting and expensive computation.
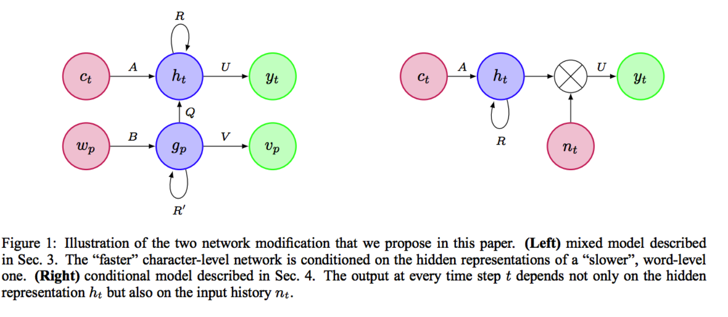 The solutions, by this work, are simple. First, leveraging word-level information, that is, condition on words in the Section 3. It is implemented by a hybrid model with a char-RNN and word-RNN (W-RNN). Then, the faster character-level network is conditioned on the hidden representations of a slower word-level one. The second solution is to directly modify the output parameters, the classifier in char-RNN. By incorporating context information in classifier, the output at every time step t depends not only on the hidden representation , but also on the input history.
The solutions, by this work, are simple. First, leveraging word-level information, that is, condition on words in the Section 3. It is implemented by a hybrid model with a char-RNN and word-RNN (W-RNN). Then, the faster character-level network is conditioned on the hidden representations of a slower word-level one. The second solution is to directly modify the output parameters, the classifier in char-RNN. By incorporating context information in classifier, the output at every time step t depends not only on the hidden representation , but also on the input history.
The deeper intuition behind these two modifications is to utilize the existed yet unexplored information in the inner mechanism of RNN.
###References
-
Stacked What-Where Auto-encoders. In submission to ICLR 2016. ↩
-
Neural Variational Inference For Text Processing. In submission to ICLR 2016. ↩
-
Reasoning in Vector Space: An Exploratory Study of Question Answering. In submission to ICLR 2016. ↩
-
Infinite Dimensional Word Embeddings. In submission to ICLR 2016. ↩ ↩2
-
Towards Universal Paraphrastic Sentence Embeddings. In submission to ICLR 2016. ↩ ↩2
-
Elman Mansimov, Emilio Parisotto, Jimmy Lei Ba & Ruslan Salakhutdinov. Generating Images From Captions With Attention. 2016. In submission to ICLR. ↩
-
Andrej Karpathy, Justin Johnson, Li Fei-Fei. Visualizing and Understanding Recurrent Networks. In submission to ICLR 2016. ↩
-
Samuel R. Bowman, Luke Vilnis, Oriol Vinyals, et al. Generating Sentences From a Continuous Spaces. 2016. In submission to ICLR. ↩
-
Piotr Bojanowski, Armand Joulin, Tomas Mikolov. Alternative Structures For Character-Level RNNs. In submission to ICLR 2016. ↩
-
Luke Vilnis, Andrew McCallum. Word Representations via Gaussian Embedding. 2015. In Proceedings of ICLR. ↩
-
Xinchi Chen, Xipeng Qiu, Jingxiang Jiang, Xuanjing Huang. Gaussian Mixture Embeddings for Multiple Word Prototypes. 2015. arXiv preprint: 1511.06246. ↩
-
Mohit Iyyer, Varun Manjunatha, Jordan Boyd-Graber, et al. Deep Unordered Composition Rivals Syntactic Methods for Text Classification. 2015. In proceedings of ACL. ↩
-
Karol Gregor, Ivo Danihelka, Alex Graves, et al. DRAW: A Recurrent Neural Network For Image Generation. 2015. arXiv pre-print. ↩ ↩2
-
Denton, Emily L., Chintala, et al. Deep generative image models using a laplacian pyramid of adversarial networks. 2015. To appear in NIPS. ↩