The LSTM architecture with the gate mechanism, is designed firstly to tackle with the “gradient vanishing” problem, a major problem in standard RNNs. It is that, error gradients vanish exponentially quickly with the size of the time lag between important events, as first realized in 1991 12. With LSTM forget gates, however, when error values are back-propagated from the output, the gradient does not vanish if the forget gate is on, which means that activation close to 1.0. Since the forget gate activation is never larger than 1.0, the gradient can’t explode either. Thus, LSTM can prevent “gradient vanishing” problem by preventing any changes to the contents of the cell over many cycles. Nevertheless, there still remains similar problems about information flow in LSTM. In this post, I will introduce some work that addresses these problems.
LSTM and their variants
Training Very Deep Networks (Highway networks)
This paper, by Rupesh Kumar Srivastava, Klaus Greff, Jürgen Schmidhuber3, has been accepted by NIPS 2015, and its previous version was published on ICML 2015 workshop. More implementation details can be found in their project page.
As said, the motivation of this paper is to address the “gradient vanishing” problem, especially when exacerbated the information flow in deeper layers. In other words, the information is blocked in “traffic problem”. And the intuition is to design mechanism, set up “special path” that rejuvenates the “traffic” in the deep networks, just like “Highway” in our real life. So, that’s where the name comes. The Highway networks.
To overcome this, we take inspiration from Long Short Term Memory (LSTM) recurrent networks. We propose to modify the architecture of very deep feedforward networks such that information flow across layers becomes much easier. This is accomplished through an LSTM-inspired adaptive gating mechanism that allows for paths along which information can flow across many layers without attenuation. We call such paths information highways. They yield highway networks, as opposed to traditional ‘plain’ networks.
I bolded the word adaptive in the quote as it is the key to their highway mechanism, the adaptive gating mechanism in the Equation (2). There are two corresponding gates, T for transform gate, C for carry gate. They together decides, for each current input in this layer, to what extent transporting it to tansformation by nonlinear layers, or allowing its passing through to deeper layers by keeping its unchanged. Based on this, the authors further extend the layerwise highway design to blockwise, applying for certain parts (e.g. dimensions) of the input.
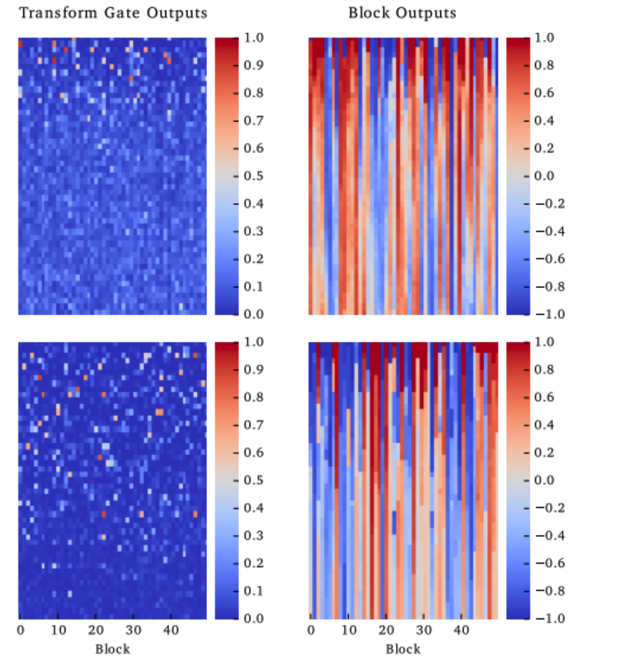
So, how many cells are being transformed? And how many cells are being carried? The analysis is shown in Figure 2 and the conclusion is that:
-
most of the cells are kept, carried, without transformation.
-
Additonally, the last column of Figure 2 displays the block outputs and visualizes the concept of “information highways”. Most of the outputs stay constant over many layers forming a pattern of stripes. Most of the change in outputs happens in the early layers (≈ 15 for MNIST and ≈ 40 for CIFAR-100).
-
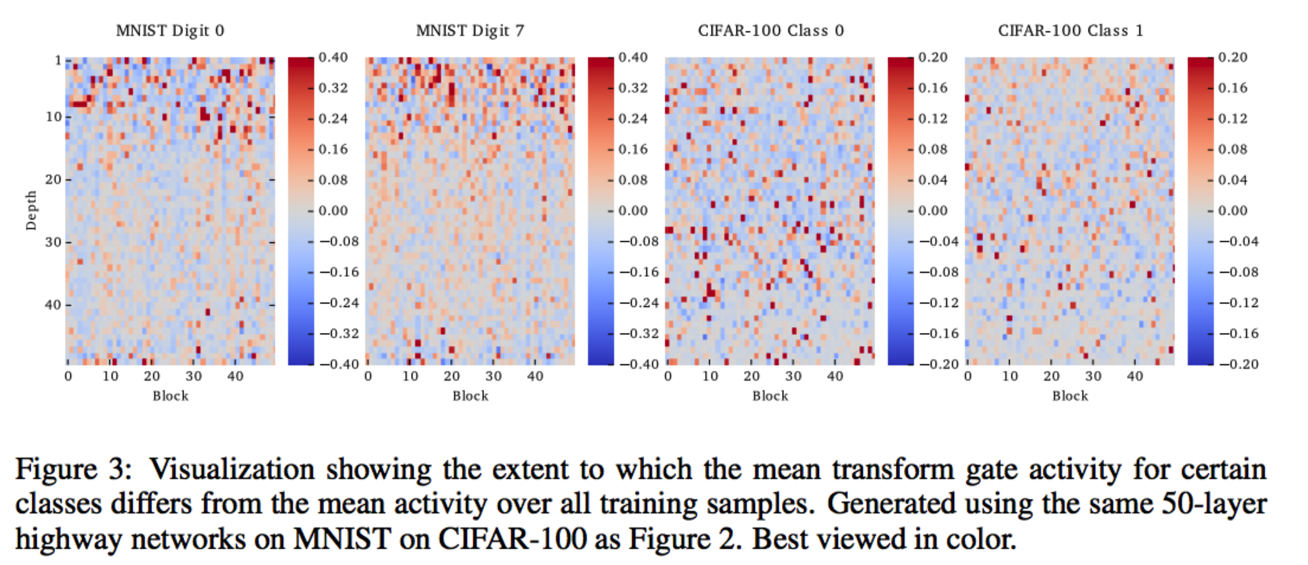
Third, does blockwise mechanism matter? The answer is revealed by different performances of dimensions in the input, in Figure 3. In each of the columns we show how the average over all samples of one specific class differs from the total average shown in the second column of Figure 2. For MNIST digits 0 and 7 substantial differences can be seen within the first 15 layers, while for CIFAR class numbers 0 and 1 the differences are sparser and spread out over all layers. In both cases it is clear that the mean activity pattern differs between classes. The gating system acts not just as a mechanism to ease training, but also as an important part of the computation in a trained network.
The highway networks has been used in many publications456.
Grid Long Short-Term Memory
The second work I want to mention is not based on LSTM. Rather, it proposes a higher framework, which is more flexible and has better computation capability, compared to LSTM. This work is done by Nal Kalchbrenner, Ivo Danihelka, Alex Graves7.
The fundamental concepts in this work are grid/block, stacked and depth. Grid/block, is a component in the new framework deciding the directions to progagate the information in the networks associated with flexible dimensions. Each dimension has its memory and hidden cells. And the 1-dimensional Grid LSTM, under their framework, seems very similar to the highway networks. The stacked concept is exactly the same as in other neural networks, except the dimension of the input remains unchanged. Stacked 2D Grid LSTM is still 2D, not 3D. What changes the dimension is the depth, which functions inside a block. The number of layers in a block is the depth of the Grid LSTM.
So, how can this framework deal with the “gradient vanishing” problem? In classical LSTM, gradient descent errors from each dimension are calculated together in each layer. Differently, Grid LSTM separate the calculation by dimensions. For each grid, there are N incoming memory cells and hidden cells, as well as N outgoings (N = size of dimension). By sharing the large H hidden layer information, the Grid LSTM holds both the interaction and information flow.
The application of their Grid LSTM is interesting, for example, Machine Translation can be transformed as a 3D Grid LSTM problem. When two dimensions are bi-LSTMs, the third dimension depth, the performance is outstanding.
LSTM: A Search Space Odyssey
The third work is so straightforward to read and understand. It is a comparison among 8 variants based on vanilla LSTM. The comparison are done by Klaus Greff, Rupesh Kumar Srivastava, Jan Koutník, Bas R. Steunebrink, Jürgen Schmidhuber8.
The comparison experiments are conducted through variable control and analysized by functional Analysis of Variance (fANOVA). The conclusions are listed explicitly in the paper. Do remember, the variants’ perfomance are highly biased with task, and the sweet take-home message is be careful with tuning learning rates.
Sequence to Sequence Learning and their variants
Let’s move to Seq2Seq Learning where LSTMs are widely adopted. Seq2Seq framework has been prefered by various tasks, such as Machine Translation, Image Captioning. It is seemingly simple yet mysterious. First, does it really own the power of “handling long term memory/information”? Second, if the first answer is yes, how to maximize such power? Third, how can we accelerate the information path between encoder and decoder in Seq2Seq learning? In the below, I will introduce several relative work under review by ICLR 2016.
Visualizing and Understanding Recurrent Networks
This work is an exntension of the famous blog, «The Unreasonable Effectiveness Of RNN» from Andrej Karpathy9.
Through controlled experiments, the work is aimed at quantatively why char-LSTM is powerful and basically, is it really able to model the often cited long term dependency? Like what is revealed in the the post by Yoav Goldberg, this work claims, the astonishing cability of char-LSTM is, yes, the log term memory, which is presented by the pairing of brackets, quotes in this work.
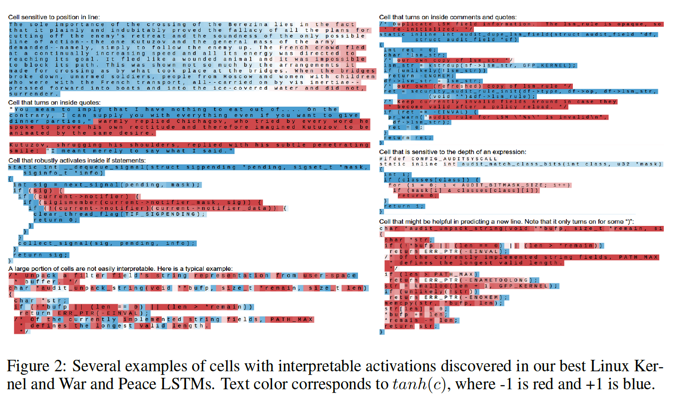 Additionally, by using visulization techniques, this work analizes the gate activation statistics and error types. The authors conclude that certain cells in char-LSTM are in charge of certain character position, demonstrating its long term memory modeling capacity in the mechanism level. The error case analysis, also proves it by reducing the errors in handling long distance information, e.g. bracket and quote.
Additionally, by using visulization techniques, this work analizes the gate activation statistics and error types. The authors conclude that certain cells in char-LSTM are in charge of certain character position, demonstrating its long term memory modeling capacity in the mechanism level. The error case analysis, also proves it by reducing the errors in handling long distance information, e.g. bracket and quote.
Generating Sentences From a Continuous Spaces
in submission to ICLR 2016, under review
I like this work very much. The second author of this work previously published a pioneering work, Gaussian embedding, in ICLR 201510. After reading both these two work, I don’t know which comes first, becasue the intuitions behind this two work are very similar.
To start with, the authors observe that the vanilla LSTM decomposes steps to prediction outputs, lacking of continuous global information, which will harms the coherence between the generated sequences. For example, the length of sentences, the part-of-speech information or the topic, can be very informative for coherence. To incorporate the global representation of sentence features, the author applies the Variational Autoencoder into RNNLM, and thus implementing a generative RNNLM with global continuous information transition.
Compared to unsupevised Sequence Autoencoder and Skip-Thought Vectors, the Variational Autoencoder RNNLM uses a posterior recognition model associated with a latent variable, \(z\), to take place of the encoder in the vanilla RNNLM. Therefore, the encoder no longer learns point-based likelihood. Rather, the distribution-based likelihood. This intuition is similar in Gaussian embedding, which learns distribution-based embeddings for words. This is the key to the coherence perserving in sentence sequences.
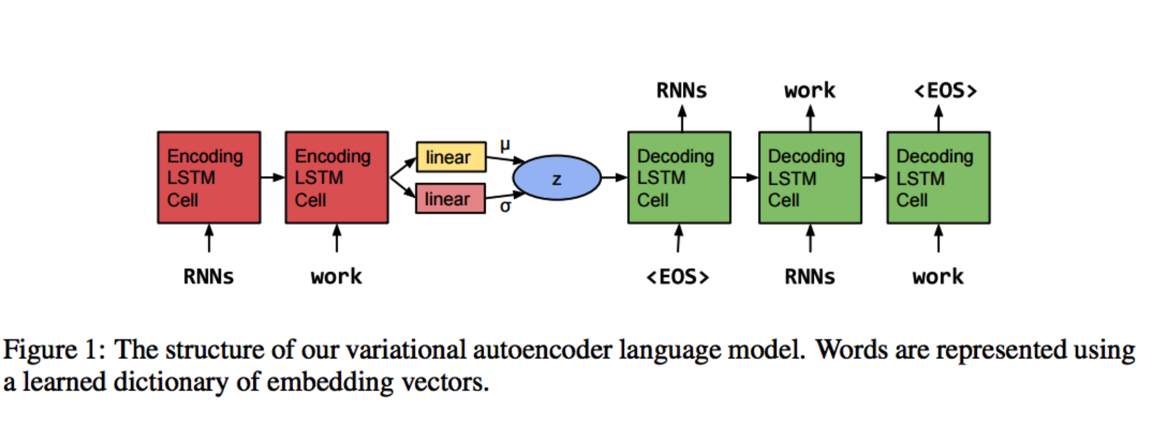
Note that this work is the first to apply the homopoly concept on sentences, as claimed in the qualitative results part in their paper. They use this concept to explore the intermediate sentences generated by the intermediate states (codes) in autoencoder. And they conclude that, they keep grammar and coherence (smooth topic transition) among these intermediate sentences. Very intuitive and interesting result.

This work also applies highway networks3 in the experiments.
Alternative Structures For Character-Level RNNs
The following two papers I want to mention motivate from the information flow improvment between encoder and decoder. The first work, is done by Facebook AI Team11.
Although char-RNN is considered beneficial for modeling subword information, it has less input/output parameters according to the smaller vocabulary size. Thus, the only way to improve its capacity is to deepen and widen the hidden layers, resulting in overfitting and expensive computation.
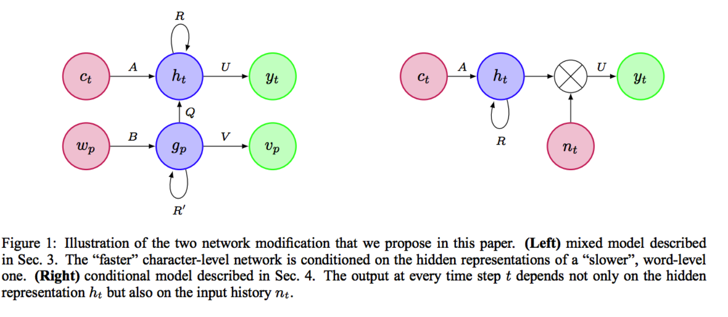 The solutions, by this work, are simple. First, leveraging word-level information, that is, condition on words in the Section 3. It is implemented by a hybrid model with a char-RNN and word-RNN (W-RNN). Then, the faster character-level network is conditioned on the hidden representations of a slower word-level one. The second solution is to directly modify the output parameters, the classifier in char-RNN. By incorporating context information in classifier, the output at every time step t depends not only on the hidden representation , but also on the input history.
The solutions, by this work, are simple. First, leveraging word-level information, that is, condition on words in the Section 3. It is implemented by a hybrid model with a char-RNN and word-RNN (W-RNN). Then, the faster character-level network is conditioned on the hidden representations of a slower word-level one. The second solution is to directly modify the output parameters, the classifier in char-RNN. By incorporating context information in classifier, the output at every time step t depends not only on the hidden representation , but also on the input history.
The deeper intuition behind these two modifications is to utilize the existed yet unexplored information in the inner mechanism of RNN.
Document Context Language Models
The second work to modify information flow between encoder and decoder, is also the last work, I want to mention in this post. It aims at improving the coherence in document representation^12.
Rather than adding latent variable into networks like what is done in the VAE-RNNLM6, this work enhances the information flow between encoder and decoder by adding additional paths for the previous history information in encoder. The model therefore introduces computational “short-circuits” for cross-sentence information. And they also use attention mechanism for further extension.
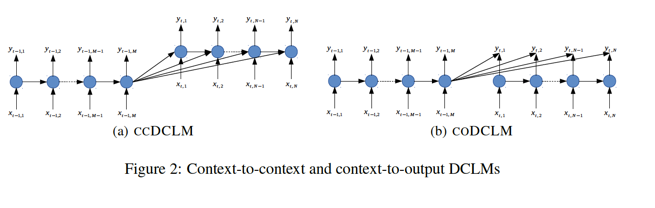
There are also other interesting work modifying Seq2Seq framework in task-specific fasion, like generating rates and reviews together by char-LSTM13, and exploring abilities of multi-task learning14.
###References
-
S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f. Informatik, Technische Univ. Munich, 1991. ↩
-
S. Hochreiter, Y. Bengio, P. Frasconi, and J. Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies. In S. C. Kremer and J. F. Kolen, editors, A Field Guide to Dynamical Recurrent Neural Networks. IEEE Press, 2001. ↩
-
R. K. Srivastava, K. Greff and J. Schmidhuber. Training Very Deep Networks. 2015. Neural Information Processing Systems (NIPS 2015 Spotlight). ↩ ↩2
-
Kim, Yoon, et al. Character-Aware Neural Language Models. 2015. arXiv preprint arXiv:1508.06615. ↩
-
Zhang et al. Highway Long Short-Term Memory RNNs for Distant Speech Recognition. 2015. arXiv preprint arXiV:1510.08983. ↩
-
Samuel R. Bowman, Luke Vilnis, Oriol Vinyals, et al. Generating Sentences From a Continuous Spaces. 2016. In submission to ICLR. ↩ ↩2
-
Nal Kalchbrenner, Ivo Danihelka, Alex Graves. Grid Long Short-Term Memory. 2015. arXiv preprint arXiV:1507.01526. ↩
-
Klaus Greff, Rupesh Kumar Srivastava, Jan Koutník, et al. LSTM: A Search Space Odyssey. 2015. arXiv preprint arXiV:1503.04069. ↩
-
Andrej Karpathy, Justin Johnson, Li Fei-Fei. Visualizing and Understanding Recurrent Networks. In submission to ICLR 2016. ↩
-
Luke Vilnis, Andrew McCallum. Word Representations via Gaussian Embedding. 2015. In Proceedings of ICLR. ↩
-
Piotr Bojanowski, Armand Joulin, Tomas Mikolov. Alternative Structures For Character-Level RNNs. In submission to ICLR 2016. ↩
-
Yangfeng Ji, Trevor Cohn, Lingpeng Kong, et al. Document Context Language Models. In submission to ICLR 2016. ↩
-
Zachary C. Lipton, Sharad Vikram, Julian McAuley. Capturing Meaning In Product Reviews with Character-level Generative Text Models. In submission to ICLR 2016. ↩
-
Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, et al. Multi-task Sequence to Sequence Learning. In submission to ICLR 2016. ↩