On the recent held ACML 2015, Professor Ruslan Salakhutdinov was invited to give a talk about «Multi-modal Deep Learning». In this post, I will follow some work from Professor Ruslan Salakhutdinov and his students to have a first look at Multi-modal Deep Learning.
Background
I will begin with the hot direction in Multi-modal Deep Learning, that is, image caption generation. It is relatively understandable of the idea behind image caption generation, similar to Machine Translation. The latter, i.e., MT, is to translate source language into another target language, whereas image caption generation is to “translate” image into caption or description. Therefore, the current hottest model in MT, i.e., the attention alignment models, also enjoys their popularity in image captioning area.
That being said, image caption has its uniqueness and thus its distinguished difficulty. For example, the granularity problem, which can be vividly illustrated by two following figures:

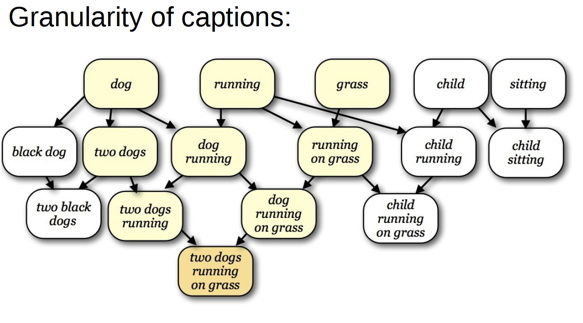
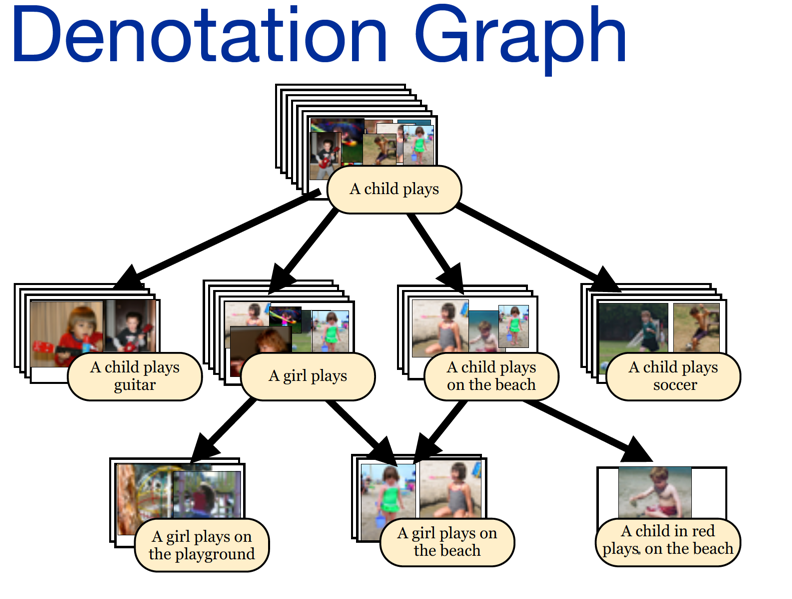
These figures demonstrates the concerns and motivations in the TACL 2014 work from P. Young, A. Lai, M. Hodosh, J. Hockenmaier1. In other words, image captioning involves granularity problem which is different from MT. In addition, this paper, as one of the pioneer work, introduces how to collect image caption training data, which also deserves a look.
##Generating Images From Captions With Attention
After some background snacks to multi-modal deep learning, I will introduce several in-area papers to delve deeper. The first comes the newest, Generating Images From Captions With Attention2, one submission to ICLR 2016.
This paper extends and combines two generative neural network models: one is the previous-introduced DRAW with differential soft attention mechanism3; the other one is the deterministic Laplacian pyramid adversarial network4 for post-processing. Upon these, the novelty of this work is to reverse “classic” image captioning, which is image->caption, to image generation, as caption->image.
Concretely,
First, they extend the DRAW model to be conditional when generating, so that it adapts to a conditional generative model, namely alignDRAW. See the upper right part of Figure 2 in their paper, \(p(x|y, Z_{1:T})\)。Such conditional extension is important for performance. As what they said,

Second, they combine alignDRAW with GAN4 to take place of the inference part. And further sharpen units are added to reduce blurrness of the images (scences). Note that the “sharpen” units are nothing to do with semantic understanding or altering. Rather, they simply function as literally “sharpen”.
Third and maybe the most important, it is relatively difficult to generate images from captions. To tackle this, the authors follow the hints from the attention mechanism, that is, when attention is imposing on “strong” words in the captions, there will be corrosponding clear objects in the image; on the contrary, the object won’t show up if its attention “fails”. This intuition is verified and specified in the experiments by substituting image elements (not only objects), which further demonstrates the advantages of their conditional alignDRAW. One advantage, for example, is its generalization. Their alignDRAW, in this work, can generate images with objects which have never been shown in training data.
Yet the success of generalization, the caption->image generation is difficult as said before. Although Deep Learning has proven effective in image object recognition (such as ImageNet task), to discriminate dog vs. cat seems too be hard under multi-modal settings. It cannot only be attributed to the complication of image generation, but also the complex of multi-modal framework, e.g., the integration of differential and deterministic networks.
Anyway, this paper is clear and easy followed. Anyone who is unfamiliar with attention model, nor with image caption generation, can get started with it and enjoy their odyssey.
##Multimodal linguistic regularities
One more step, I want to slide to one attractive slide, in the talk from Professor Ruslan Salakhutdinov, that is, Multimodal linguistic regularities. Remember the tipping point of word2vec, king - man + woman = queen? That is a kind of linguistic regularities. So, multimodal linguistic regularity will be something like this:

Using the intuition in the alignDRAW work, there comes a naive approach to implement such multimodal linguistic regularity. Just replace the word(s) in the caption with strong attention(s), in subject to little change in the attention(s), the \(\alpha\)(s), and then we can get the “customized” linguistic regularity perseving image. Let’s see one “customized” service, the color:

As color is the fundamental and thus “simple” element in image task, it is expected to see more interesting “customized” service. So, how about these?

All these slides come from Ryan Kiros, one student of Professor Ruslan Salakhutdinov and in his share at CIFAR Neural Computation and Adaptive Perception Summer School 20145.
Note that attention is only a naive way, maybe too naive, to implement the multimodal linguistic regularities. To become more powerful and general, one need, at least, to understand the structures/relations between objects, which remain open!
##Order-Embeddings Of Images And Language
So, is there some work that directs in structure-aware image captioning? The answer is yes. Another ICLR 2016 submssion6 is on their way.
It follows the line of relation embedding, but differs in the richness of relation. Most previous work of relation embedding limit in symmetric or binary relation. Motivated by this, this work6 aims at modeling asymmetric and hierarchical orders to capture visual-semantic hierarchy, which exists broadly among objects, caption words and sentences.
The following figure in the paper illustrates what is visual-semantic hierarchy.
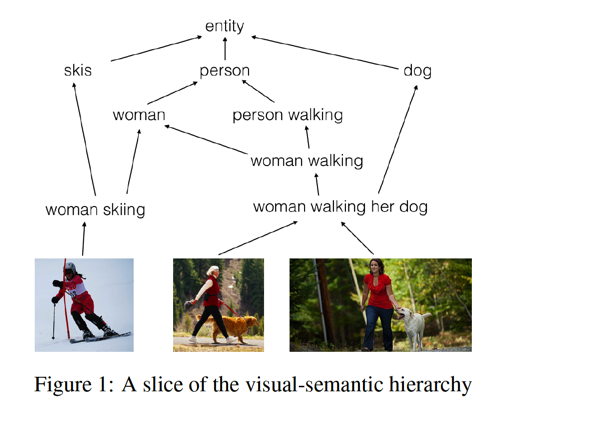
The pictures in the last row, along with the captions as well as the words and phrases in the captions, build up the partial ordered hierarchy. And the goal of this work is to learn caption representation and image representation, in subject to preserving such partial order. In my view, which has not been explicit in the paper, such partial order is a good cross point, meeting another facet of granularity problem in image captioning, and the structure understanding in multi-modal linguistic regularity.
In practice, the novelty of this work is the definition of the partial order and its space, which serves as the basis for asymmetric penalty on partial order embedding learning. Another figure in the paper gives more understandable about the richer relation that order embedding can learn.
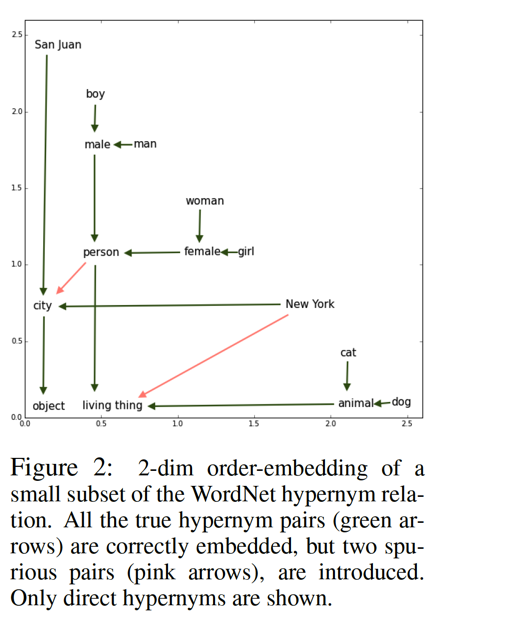
With this richer capacity, their approach performs well on hypernym prediction, image caption retrieval and natural language inference. And at last of the paper, the authors discuss some difficulties of granularity problem in hope of pointing out some intuitions about such partial order.
##Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books
Now, let’s move beyond single image-caption pair. I will introduce a work, focusing on pairing a set of images and dialogue. This ICCV 2015 work7, aligns book-movie by using movie shots and series of lines in the book.
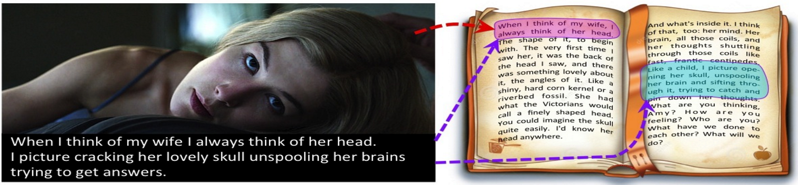 The above picture is the banner of their project page, which depicts the movie «Gone Girl». In this movie, the heroine’s diary plays as the background narrator. This is a perfect example of the alignment between books and movies. To achieve this, this work defines several shots as the movie and corresponding subtitles as dialogue. What also worth mentioning is that as they are handling with sentence-level information, they use the newly proposed Skip-Though Vectors8.
The above picture is the banner of their project page, which depicts the movie «Gone Girl». In this movie, the heroine’s diary plays as the background narrator. This is a perfect example of the alignment between books and movies. To achieve this, this work defines several shots as the movie and corresponding subtitles as dialogue. What also worth mentioning is that as they are handling with sentence-level information, they use the newly proposed Skip-Though Vectors8.
Finally, such alignment can then be used for shot (image) caption with similarity calculation:

##Deep Compositional Captioning: Describing Novel Object Categories without Paired Training Data
As mentioned before, although Deep Learning has proven effective in image object recognition (such as ImageNet task), to discriminate dog vs. cat seems too be hard under multi-modal settings.
To this end, one fresh work9 motivates to bridge the gap between single-modal object recognition to multi-modal image captioning. In this work, the authors argue that the image-caption pair training sets are far smaller than single image object recognition sets. Following the transfer learning, they develop the so-called Deep Compositional Captioner (DCC) model, which consists of two seperate models, i.e., object lexical classifier and language model, as well as one intermediate multi-modal layer. The separate lexical classifier is designed to utilize the single object recognition model, such as those trained solely on image sets, e.g., ImageNet. Thus, the knowledge learned in the separate classifier can be transfered to multi-modal DCC via the intermediate layer. They give an example to demonstrate the power of such composition:
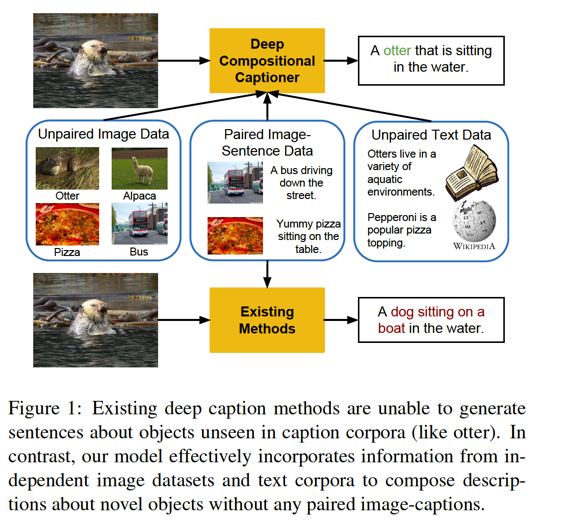
In sole imaga-caption training sets, there is only dog label and thus current image-caption trained captioners are limited to falsely caption its as dog. However, with DCC in this work, the animal in the picture can be correctly recognized as otter, which is included in ImageNet sets but missing in image-caption pair sets.
This work is straightforward yet ad-hoc. I will look forward to further work of better scalability.
##Exploring Models and Data for Image Question Answering
The last paper I will include in this post is something close to the ultimate goal in Multi-modal Deep Learning, a paper from Toronto University (again), accepted by NIPS 1510.
So, why I call this someone close to the ultimate goal? What is the ultimate goal? In my mind, multi-modal, especially image-text, is (still) aimed at understanding the world. The text, the language we use to describe the world, and the image, the snapshots of the world, are often corresponded to represent the information. To understand the world, we need to understand the language, and we also need to understand the image. To evaluate and judge whether the models are able to understand the language, researchers design NLP tasks, such as question answering. Similarly, one can do image question answering to asset the multi-modal capacity. This line has attracted some researchers since 2014 and the NIPS 15 paper I will introduce here is one among them.
Currently, the image QA evaluation dataset is relatively simple and limited in three types of questions: what type of object is, how many objects are, what colors are. These questions are the fundamental aspects of image understanding, though, some of which require higher ability to be aware of structures/relations among objects in the image, for example,

In the last, don’t forget that there still exists various types of multi-modal beyond image-text, such as video-text (action recognition), speech-text (speaker adaption) and so on. This is a new area and thus challenging and promising, as said in the old saying.
###References
-
P. Young, A. Lai, M. Hodosh, J. Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. 2014. TACL. ↩
-
Elman Mansimov, Emilio Parisotto, Jimmy Lei Ba & Ruslan Salakhutdinov. Generating Images From Captions With Attention. 2016. In submission to ICLR. ↩
-
Karol Gregor, Ivo Danihelka, Alex Graves, et al. DRAW: A Recurrent Neural Network For Image Generation. 2015. arXiv pre-print. ↩
-
Denton, Emily L., Chintala, et al. Deep generative image models using a laplacian pyramid of adversarial networks. 2015. To appear in NIPS. ↩ ↩2
-
Ryan Kiros. Generating image captions with neural networks. CIFAR Neural Computation and Adaptive Perception Summer School, University of Toronto, 2014. ↩
-
Ivan Vendrov, Ryan Kiros, Sanja Fidler, Raquel Urtasun. Order-Embeddings Of Images And Language. 2016. In submission to ICLR. ↩ ↩2
-
Yukun Zhu, Ryan Kiros, Richard Zemel, et al. Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. 2015. In Proceedings of ICCV. ↩
-
Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, et al. Skip-Thought Vectors. 2015. To appear in NIPS. ↩
-
Lisa Anne Hendricks, Subhashini Venugopalan, Marcus Rohrbach, et al. Deep Compositional Captioning: Describing Novel Object Categories without Paired Training Data. 2015. arXiv preprint. ↩
-
Mengye Ren, Ryan Kiros, Richard Zemel. Exploring Models and Data for Image Question Answering. 2015. To appear in NIPS. ↩