
《Improving Word Representations via Global Context and Multiple Word Prototypes》这篇论文意在用全文信息辅助局部信息和多个词向量共同表示一个词的方法,增强语义。不止如此,在我看来,这篇论文最重要的地方有四个:首先的思想是 word disambiguation 在 context level;第二个是用 C&W 的 ranking loss 会比以前的 log-likelihood 训练速度快。第三个是把 local 和 global 的两种 score 设计成 NN 中的两个 part,分别用一层 hidden layer 学习。但是这里他们只用了简单的加法,而没有线性权重参数 $\alpha$。后人许多改进了 $\alpha$,还做了些参数对比展示实验结果。不过本质没区别。第四个是他们并没有直接用 SGD,二是用了 1000 的 mini-batch L-BFGS,这点好像追随的人不多。
DeepWalk Online Learning of Social Representations
《DeepWalk: Online Learning of Social Representations》是一篇我个人非常喜欢的论文,不仅提出了一个想法,更展示了这个想法的可行性和可能空间。提出的想法是利用网络结构信息将用户表示为低维实值向量,学出来的表示是最重要的,因为有了表示就可以用来加在许多其他任务上。
Collections of Tips for Machine Learning
收集了一些我觉得真的有用实战机器学习的文章。比如如何调参,比如会遇到什么真实数据带来的问题,如何 debug,如何 speed-up。长期更新。
Advice for applying Machine Learning
主要集中在如何观察数据来选择方法。
How to Debug Learning Algorithm for Regression Model
主要都是讲回归中遇到的各种“预期不符”的结果。配合 ESL 第二章和第三章内容看效果加成。
这篇是综合翻译,没给出都从哪节选的。我收集的英文版在下面:
Training Tricks from Deeplearning4j
deeplearning4j 的 googlegroups 也很推荐。这篇其实干货不多,但是也有一些了。包括对于训练的理解,并不全是干货般的总结。
Suggestions for DL from Llya Sutskeve
Hinton 亲传弟子介绍深度学习的实际 tricks,包括data, preprocessing, minibatches, gradient normalization, learning rate, weight initialization, data augmentation, dropout和ensemble。
Efficient Training Strategies for Deep Neural Network Language Models
讨论了如何设置 batch-size, initial learning rate, network initialization,但最有趣的结论应该是:普通的 deep feed-forward architecture比recurrent NN 在 model long distance dependency 效果和效率都更好。
Uber 的 data scientist 写的。比如: Rectifier is becoming popular as an activation function. However, I find its theory dubious and my experiments have not shown that it is always better. That said, I’m experimenting with new activation functions. (Little trivia: I’m borrowing many ideas from my graduate work in computational wave propagation.)
Large-scale L-BFGS using MapReduce
NIPS’14 的论文,简单并行化 LBFGS里面的双循环(最耗时,计算量巨大)。
特征工程系列文章:Part1.单变量选取 Part2.线性模型和正则化 Part3.随机森林 Part4.稳定性选择法、递归特征排除法(RFE)及综合比较。有 Python 代码。
机器学习代码心得之有监督学习的模块 机器学习代码心得之迭代器和流水处理
新一代大神陈天奇怪的系列文章,有兴趣的直接顺着看吧。
STOCHASTIC GRADIENT BOOSTING: CHOOSING THE BEST NUMBER OF ITERATIONS
Kaggle达人YANIR SEROUSSI告诉你如何选择Stochastic Gradient Boosting的训练最佳iteration超参数。不过我比较存疑,因为如果条件允许,当然迭代的越多越好……
Large-Scale High-Precision Topic Modeling on Twitter
Twitter 高级研究员的 KDD’14论文。有不少实用技巧,比如短文本特征,LR结果概率化修正,正样本抽样,PU学习后负样本选取。
How transferable are features in deep neural networks?
也是争议比较大的一篇文章,finetuning 有一定帮助,但是不够细致。
有心人整理的 Hinton 提到的 Dark Knowledge 的一些资源。
Stochastic Gradient Descent Tricks
L eon Bottou 写的 Stochastic Gradient Descent Tricks 挺好,做工程也要做的漂亮。
翻译文章。神经网络训练中的Tricks之高效BP(反向传播算法),来自与于《Neural Networks: Tricks of the Trade》一书第二版中的第一章 Efficient BackProp 的部分小节。
Deep Learning for Vision: Tricks of the Trade
Marc’Aurelio Ranzato 在 CVPR 上 的 presentation slides/talk(Youtube 等地方可以搜到)。caffe 作者之一贾扬清推荐。涉及到了许多 DL 的调参技巧(在 slides 比较靠后的地方)
我是这样进行知识管理的
写这篇博客是前几天看到别人分享 pluskid 的《关于知识整理、积累与记忆》,加之我自己一直以来也很关注这件事,也有一点点心得。整理出来自己回顾,和大家讨论。
Github Pages Categories with Jekyll
When Jekyll is friendly to tags in post, it is not that .
There are three questions that you’ll encounter using categories: (1) Multiple word category name; (2) Multi categories; (3) Archive posts by a specific category.
##Multiple word category name
When we want to name a category using multiple words (more than 1 word, contains spaces), jekyll will defaulty generate a permalink with the form http://domain.com/category/year/month/title and result in urls with dashes. It is the case and not bugs. We cannot easily change the permalink settings for the way Jekyll generates urls for posts in the config form but this can be done with a plugin.
But, Github Pages just forbid any plugins. Thus, it will work on your own server other than blogs on Github Pages. Therefore, I suggest no spaces in category names.
##Multi categories
The second question is we sometimes want to category one post into multiple categories, like tags. Here we need to be careful with the frontmatters. Jekyll requires that Markdown files have front-matter defined at the top of every file. And for categories, it provides two formats of frontmatters. In the Jekyll’s documentations, both category and categories are available.
Is there any differences? Sure. When we just need only one category, we can use both
category: This is one category
and
categories: This is one category
But, you’ve may got that when comes to multiple categories, we can only use categories and carefully using two formats below:
categories
- This is one category
- This is another category
or the square brackets way:
categories: ['The is a category', 'This is another category']
It makes sense.
So, the further question is, are category and categories really same when only one category? Actually, they don’t have the same effect on post object. When declaring category, post.category (string) and post.categories (array) are set. When declaring categories, only post.categories is set. Be careful!
##Archive posts by a specific category
But problems still show up when we want to archive the posts by a specific category. We may first try something like this:
{% for post in site.categories.'This is one category' %}
...
{% endfor %}
or this:
{% for post in site.posts | where: 'category','This is one category' %}
...
{% endfor %}
If you tried, you failed. It is because you cannot put a filter on a loop. You have to capture first, then loop:
{% capture myposts %} { { site.posts where: 'category','This is one category' } }
{% endcapture %}
{% for post in myposts %}
...
{% endfor %}
Speed of Mini-Batch SGD
This post comes from a friend’s question, that he says sometimes mini-batch SGD converges more slowly than single SGD.
Let’s begin with what these two kinds of method are and where they differ. Here notice that mini-batch methods come from batch methods.
##Batch gradient descent
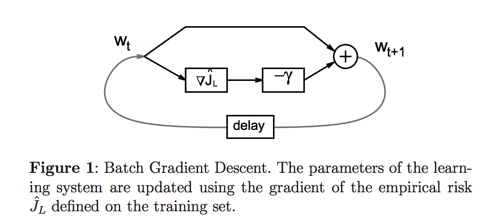
Batch gradient descent computes the gradient using the whole dataset, while Stochastic gradient descent (SGD) computes the gradient using a single sample. This is great for convex, or relatively smooth error manifolds. In this case, we move directly towards an optimum solution, either local or global.
###pros
- Great for convex, or relatively smooth error manifolds because it directly towards to the optimum solution.
###cons
- Using the whole dataset means that it is updating the parameters using all the data. Each iteration of the batch gradient descent involves a computation of the average of the gradients of the loss function over the entire training data set. So the computation cost matters.
##Stochastic gradient descent
While Batch gradient descent computes the gradient using the whole dataset, Stochastic gradient descent (SGD) computes the gradient using a single sample.
###pros
-
Obviously SGD’s computationally a whole lot faster.
-
Single SGD works well better than batch gradient descent when the error manifolds that have lots of local maxima/minima.
###cons
- Sometimes, with the computational advantage, it should perform many more iterations of SGD, making many more steps than conventional batch gradient descent.
##mini-batch SGD
There comes the compromise of this two kinds of methods. When the batch size is 1, it is called stochastic gradient descent (GD). When you set the batch size to 10 or to some extend larger, this method is called mini-batch SGD. Mini-batch performs better than true stochastic gradient descent because when the gradient computed at each step uses more training examples, mini-batches tend to average a little of the noise out that single samples inherently bring. Thus, the amount of noise is reduced when using mini-batches. Therefore, we usually see smoother convergence out of local minima into a more optimal region.
Thus, the batch size matters for the balance. We primally want the size to be small enough to avoid some of the poor local minima, and large enough that it doesn’t avoid the global minima or better-performing local minima. Also, a pratical consideratio raises from tractability that each sample or batch of samples must be loaded in a RAM-friendly size.
So let’s be more clear:
##Why should we use mini-batch?
- It is small enough to let us implement vectorization in RAM.
- Vectorization brings efficiency.
##Disadvantage of mini-batch SGD is the difficulty in balancing the batch size \(b\).
However, in the paper Sample size selection in optimization methods for machine learning, the author points out that though large mini-batches are preferable to reduce the communication cost, they may slow down convergence rate in practice. And Mu Li in this papar is dealing with this problem.
##Ref
[1]Bottou, Léon. Large-scale machine learning with stochastic gradient descent. Proceedings of COMPSTAT’2010. Physica-Verlag HD, 2010. 177-186.
[2]Bottou, Léon. Online learning and stochastic approximations. On-line learning in neural networks 17.9 (1998): 142.
[3]Li, Mu, et al. Efficient mini-batch training for stochastic optimization. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014.
ADMM 框架小结
ADMM 是这两年很火的一个算法框架。
其主要的提出想法是为了“分布式”的解决一类问题,即: \(min f(x) + g(y) s.t. Ax + By = c\) 是等式约束(不可以是不等式)的最小化加和问题;且此时 f(x) 和 g(y) 是两类性质非常不同的函数,比如 LASSO 中的 1-norm 惩罚和前面的代价函数。
对于这个问题的 augmentated Lagrangian:
\[L_{\rho}(x,z,y)=f(x)+g(z)+y^T(Ax+Bz-c)+(\rho/2)\|Ax+Bz-c\|_2^2\]和对应的 update rule:
\[x^{k+1}=\arg\min_x L_{\rho}(x,z^k,y^k)\] \[z^{k+1}=\arg\min_z L_{\rho}(x^{k+1},z,y^k)\] \[y^{k+1}=y^k+\rho(Ax^{k+1}+Bz^{k+1}-c)\]可以看出,上图中的第一个式子和第二个式子是乘子法的一个特殊化;且第一个式子对应的是乘子法中的”x-minimization step”,第二个式子是所谓的“dual update”。
不同的是,乘子法是同时计算并最小化x,z: \((x^{k+1},z^{k+1})=\arg\min_{x,z} L_{\rho}(x,z,y^k)\)
而ADMM中,x,z 是“alternated”计算的,它 decouples x-min step from y-min step。
这里可以看到,augmentated Lagrangian 虽然弱化了乘子法的强假设性,但 x-min step 引入了二次项而导致无法把 x 分开进行求解。所以 ADMM 也是就是期望结合乘子法的弱条件的收敛性以及对偶上升法的可分解求解性。
其实 ADMM 也是一个需要 trick 的框架:
-
因为它的缺点是需要非常多步的迭代才能得到相对精确的解,这就好像是一阶算法。
-
另外,对 $\rho$ 的选择也很重要,非常影响收敛性;$\rho$ 太大,对于 min (f1+f2) 就不够重视;反之,则对于 feasibility 又不够重视。Boyd et al. (2010) 倒是给了实践中改变 $\rho$ 的策略,可是也没有证明它的收敛性。
Boyd 在其网站上给出了一些例子。总结这里的几个例子,构造 ADMM 的形式,主要思想就是往直前的受约束的凸优化问题靠拢。 (1)对于只有传统损失函数没有正则项的(比如LAD, Huber Fitting),构造出一个 z。 (2)对于有约束的,比如 l1-norm 的约束,则把约束变成 g(x),原始损失函数为 f(x)。若 f(x) 本身没有(比如Basic Pursuit),就构造成带有定义域约束的 f(x)(某种投影);如果有,则就是比较一般化的损失+正则问题,这时候就基本是一个\(f(x)+\lambda\|z\|_1\)的形式。是非常自然的 ADMM。
所以,像广义线性模型和广义可加模型+正则等等都非常适合 ADMM。
Ref:
[1] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, 2010.
[2] S. Boyd. Alternating Direction Method of Multipliers (Slides)
Relation Extraction with Matrix Factorization
This post is about the NAACL’13 Accepted Paper, Relation Extraction with Matrix Factorization and Universal Schemas. The talk is available on techtalks.
And then present some basic knowledge of Matrix Factorization.
Abstract
The paper studies techniques for inferring a model of entities and relations capable of performing basic types of semantic inference (e.g., predicting if a specific relation holds for a given pair of entities). The models exploit different types of embeddings of entities and relations.
This problem is usually tackled either via distant weak supervision from a knowledge base (providing structure and relational schemas) or in a totally unsupervised fashion (without any pre-defined schemas). The present approach aims at combining both trends with the introduction of universal schemas that can blend pre-defined ones from knowledge bases and uncertain ones extracted from free text. This paper is very ambitious and interesting.
Related Work
relation extraction
There has been a lot of previous research on learning entailment (aka inference) rules (e.g., Chkolvsky and Pantel 2004; Berant et al, ACL 2011; Nakashole et al, ACL 2012). Also, there has been some of the very related work on embedding relations, e.g., Bordes et al (AAAI 2011), or, very closely related, Jenatton et al (NIPS 2012).
Matrix Factorization
Matrix factorization as a technique of Collaborative filtering has been the preferred choice for recommendation systems ever since Netflix million competition was held a few years back. Further, with the advent of news personalization, advanced search and user analytics, the concept has gained prominence.
In this paper, columns correspond to relations, and rows correspond to entity tuples. By contrast, in (Murphy et al., 2012) columns are words, and rows are contextual features such as “words in a local window.” Consequently, this paper’s objective is to complete the matrix, whereas their objective is to learn better latent embeddings of words (which by themselves again cannot capture any sense of asymmetry).
Save Storage
Although the paper doesn’t explicit point out how common is it that a tuple shares many relations, it remains concern. The experiments seem to show that mixing data sources is beneficial.
Trends
The researchers are ambitious to bridge knowledges bases and text for information extraction, and this paper seems to go along this trend. However, the paper’s scheme is limited before complex named entity disambiguation is solved, since it relies on the fact that entities constituting tuples from the Freebase and tuples extracted from the text have been exactly matched beforehand.
Generalized Matrix Factorization
It has been a general machine learning problem formulated as:
Training data
- V: m x n input matrix (e.g., rating matrix)
- Z: training set of indexes in V (e.g., subset of known ratings)
Parameter space
- W: row factors (e.g., m x r latent customer factors)
- H: column factors (e.g., r x n latent movie factors)
Model
- \(L_{ij}(W_{i*},H_{*j})\): loss at element (i,j)
- Includes prediction error, regularization, auxiliary information, . . .
- Constraints (e.g., non-negativity)
Find best model
\[\arg\min_{W,H}\sum_{(i,j)\in Z}L_{i,j}(W_{i*},H_{*j})\]Stochastic Gradient Descent for Matrix Factorization
Among the various algorithmic techniques available, the following are more popular: Alternating Least Squares (ALS), Non-Negative Matrix Factorization and Stochastic Gradient Descent (SGD). Here I only presents SGD for MF.
SDG is a well know technique which tends to compute direction of steepest descent and then takes a step in that direction. Among the variants include:
(a)Partitioned SGD: distribute without using stratification and run independently and in parallel on partitions (b)Pipelined SGD: based on ‘delayed update’ scheme (c)Decentralized SGD: computation in decentralized and distributed fashion
The main solution is as follows:
-
Set \(\theta = (W,H)\) and use
\(L(\theta)=\sum_{(i,j)\in Z}L_{ij}(W_{i*},H_{*j})\),
\({L}'(\theta)=\sum_{(i,j)\in Z}{L}'_{ij}(W_{i*},H_{*j})\),
\({\hat{L}}'(\theta,z)=N{L}'_{i_{z}j_{z}}(W_{i_{z}*},H_{*j_{z}})\), where \(N=\vert Z\vert\) -
SGD epoch
- Pick a random entry \(z \in Z\)
- Compute approximate gradient \({\hat{L}}'(\theta,z)\)
- Update parameters \(\theta_{n+1}=\theta_{n}-\epsilon_{n}{\hat{L}}'(\theta,z)\)
- Repeat \(N\) times
SVM V.S. FM
FM is short for Factorization Machine. Indeed, it can be interpreted as Factorization Methods and Support Vector Machine. It is firstly published by Steffen Rendle.
Factorization machines (FM) are a generic approach that allows to mimic most factorization models by feature engineering. This way, factorization machines combine the generality of feature engineering with the superiority of factorization models in estimating interactions between categorical variables of large domain. libFM is a software implementation for factorization machines that features stochastic gradient descent (SGD) and alternating least squares (ALS) optimization as well as Bayesian inference using Markov Chain Monte Carlo (MCMC).

in SVM mode, \(y(x)=w\cdot x+b=w_{u}+w_{i}+...+b=\sum w_{i}x_{i}+b\), but original SVM fails with 2 main problems using here: Real Value V.S. Classification, and Sparsity.
in Factorization Machine mode, it is solved as: \(y(x)=\sum w_{i}x_{i}+\sum\sum(v_{i}\cdot v_{j})x_{i}x_{j} +b\). The second part in the formula is Factorization, where the transformation from original SVM to FM lies.


FM V.S. MF
- FM: \(y(x)=\sum w_{i}x_{i}+\sum\sum(v_{i}\cdot v_{j})x_{i}x_{j} +b\)
- MF: \(y(x)=w_{u}+w_{i}+v_{u}\cdot v_{i} + b\)
Incorpating Domain Knowledge into LDA
Recent years, there has been emerging research on knowledge-based models and methods. Researchers have tried in various ways to express/embed/structure the knowledge and then incorporating them into some existing models, among which is LDA (Latent Dirichlet Allocation).
For further detailed about LDA, please investigate through [Blei el al., 2003]. The basic idea and foundation of LDA is handling word co-occurrence pattern to discover the latent semantic meaning. The simple model has limited resolution to deeper latent sementics and thus the variations of LDA are bursting. One focus to expand LDA is how to incorporating more prior knowledge into it.
Types of Prior Knowledge
Basically, all types of knowledge incorporation is to change the prior distribution of Dirichlet setting in LDA.
a. 在传统 LDA 里,有两组先验,一种是文档~主题的先验,来自于一个对称的\(\mathcal Dir(\alpha)\);一种是主题~词汇的先验,来自于一个对称的\(\mathcal Dir(\beta)\) ——都是 symmetric Dirichlet Distribution。所以按理,可以把这两种先验分别改成不对称的——这样就加入了更多的 knowledge 信息。
b. 在 Rethinking LDA 里一文1中,结合两种先验与两种不同的先验设定方法,可以得到以下四种组合:
- AA:文档~主题分布和主题~词汇分布都采用非对称;
- AS:文档~主题分布采用非对称的先验,而主题~词汇分布采用对称的先验;
- SA:文档~主题分布采用对称的先验,而主题~词汇采用非对称;
- SS:文档~主题分布和主题~词汇分布都采用对称的先验。
他们的实验发现其中 AS 的方法可以更高地提高 LDA 对于文本建模的能力。
c. 典型的打破“对称”文档~主题分布先验(AS)的几个model,有很好理解的 Twitter-LDA,也有 Behavior-LDA。同时,supervised-LDA 也可以看做一个非结构化的打破先验的方式,变形后有 SeededLDA(在两个层次的先验都通过设计加入了不对称信息)。
d. 除了通过直接地改变概率分布来加入先验的方法,这几年来开始有越来越多的研究者想将结构化的先验知识加入 LDA 。这种结构化的先验,不再是简单的 prior distribution,更可以倾向于称为“knowledge”。这样的研究之所以盛行,一方面是长期以来的结构化知识库已有很多(且因为还要继续建立知识图谱等,结构化仍将是未来的趋势),另一方面形式语言(逻辑语言)的表示的研究一直都没有停止。这种结构化的引入 knowledge 的方法,本质也是通过打破先验设定的 symmetric Dirichlet Distribution。下文将重点总结这方面的工作。
Domain-dependent Model:
-
CIKM’13 里,Zhiyuan Chen(也在 Bing Liu那里)的一篇 Discovering Coherent Topics2 里将 incorporating knowledge 的研究分成了 domain-dependent 的和 domain-independent:前者是 expert 知道(普通人不一定熟悉,需要 expert 来参与编辑)的知识而且有知识领域限制,后者是各领域通用的一些知识。
-
同样是上述文章,提到了3,4,5,6,7 的论文都是 domain-dependent knowledge-based 的。
-
其中,Dirichlet Forest3 和 Jerry Zhu 的 First-Order Logic4 的形式化加入 domain-knowledge 的方法还是比较有代表性。前者是将领域内一定会一起出现(两个词的出现概率都很大或者都很小)的词和一定不能一起出现的词分别表示为 Must-Link 和 Cannot-Link,然后表示成树中的结点和结点之间的连接关系。但这个 Link 关系是可传递的,所以会导致“错误”的先验知识加入(CIKM’13 中提到了这点)。
Domain-independent Model:
-
按照 Zhiyuan Chen 的说法,他们在 CIKM’13 里提出的 GK-LDA2 应该是第一个 domain-independent model。所以这个部分只谈他们的那篇论文(GK-LDA 是 General Knowledge 的缩写,即 domain-independent 的 knowledge)。
-
在这篇论文里,他们的假设是,there is a vast amount of available in online dictionaries or other resources that can be exploited in a model to generate more coherent topic. 而通过 extract,就可以把这样的 lexical knowledge 提取成 a general knowledge base.
-
他们采取的知识表达结构是 lexical relationships on words. 简称 LR-sets。LR-sets 有很多种关系,比如同义词、反义词,这篇文章中重点讲的是 adjective-attribute 这种 relationship,e.g. (expensive-price).
-
他们提出的 GK-LDA 依然是 一种 LDA 的变形,而且是基于他们组再之前的工作——IJCAI’13 的 Leveraging Multi-Domain Prior Knowledge8 里的 MDK-LDA。
从 MDK-LDA (b) 到 MDK-LDA 到 GK-LDA:
-
主要总结 Zhiyuan Chen 的两篇工作,之前提过的 MDK-LDA 和 GK-LDA。
-
MDK-LDA 是 multi-domain knowledge 的缩写,从思想上来看是一种 Transfer Learning 的想法,prior from other domain can help topic model in new domain.
-
所谓的 multi-domain 可以通过 s-set 表示,比如 “light” has 2 s-set {light, heavy, weight} 和 {light, bright, luminanee},表示出了 light 的两个词义。那么这个工作就是去 leverage 这个 s-sets。
-
他们在 IJCAI’13 的那篇里8 主要分析了 之前的 domain-knowledge 会遇到的两个大问题,MDK-LDA 解决了其中一个 adverse effect 的问题,而 GK-LDA 两个都解决了(还有一个是错误先验知识带来的问题)。MDK-LDA 解决的主要在 LDA 问题里,如何使得一些少见的词但是确实是同一个 set 里的词的低频不会影响 topic modeling 的学习(不仅仅用 TF-IDF 消除影响),那么他们认为 the words in an s-set share a similar semantic meaning in the model should redistribute the probability masses over words in the s-set to ensure that they have similar probability under the same topic. 这个思想使得他们在 MDK-LDA(basic) 之上加入了 GPU 9:像抽出小球再放回同颜色的球的思想一样,去改变同一个 s-set 里的 word 的dist.
-
在 MDK-LDA 之上,解决第二个问题的就是 GK-LDA,也就是在 CIKM’13 里的那篇2。MDK-LDA 没法避免当我们的先验 s-set 是错误的(这也是其他许多 domain-dependent model 的问题,必须保证我们的先验知识都是正确的)对 performance 的影响。 GK-LDA 加入了一个 word correlation matrix 的计算 和 加入一个 threshold,减少了 wrong LR-set 的的影响。
-
其中加入 GPU 的思想,和 CRP 中如何改变人坐在具体某个餐桌的概率的思想是一致的(只是一个模型的不同解释)。
Footnotes
-
Transfer Learning 和 Active Learning、Online Learning 等等都有关系。这部分内容还没有系统学习过,之前一篇文章也有提到这里的一个小坑。
-
GPU9,是 Generalized Polya Urn 的简称。搞懂 LDA 必须先学习的模型。将这个过程generalized, 可以推向Polya Urn’s Process。Polya Urn’s Model 是比较直观的理解 Dirichlet Process 的一种解释模型。模型中抽出球再放回就是对当前的多项分布进行抽样(同时不改变该分布),又放回一个同样的球就是依当前多项分布产生新的多项分布。假设从\(\mathcal Dir(\alpha, K)\)中抽样,那么新产生的多项分布共有 K 个,其概率质量与当前多项分布成比例。K 个新产生的多项分布的加权平均与原多项分布是同分布的。而在之前的 CIKM’13 论文2中就是通过改变每次放回的“球”(LR-set 里同一个 set 的词)的“颜色”和数量来改变 prior knowledge 的。这种思想感觉还是很赞的。
Reference
-
Hanna Wallach, David Mimno and Andrew McCallum. Rethinking LDA: Why Priors Matter. NIPS, 2009, Vancouver, BC. ↩
-
Zhiyuan Chen, Arjun Mukherjee, Bing Liu, Meichun Hsu, Malu Castellanos, and Riddhiman Ghosh. Discovering Coherent Topics using General Knowledge. Proceedings of the ACM Conference of Information and Knowledge Management (CIKM’13). October 27 - November1, Burlingame, CA, USA. ↩ ↩2 ↩3 ↩4
-
Andrzejewski, D., Zhu, X. and Craven, M. 2009. Incorporating domain knowledge into topic modeling via Dirichlet Forest priors. ICML, 25–32. ↩ ↩2
-
Andrzejewski, D., Zhu, X., Craven, M. and Recht, B. 2011. A framework for incorporating general domain knowledge into latent Dirichlet allocation using first-order logic. IJCAI, 1171–1177. ↩ ↩2
-
Burns, N., Bi, Y., Wang, H. and Anderson, T. 2012. Extended Twofold-LDA Model for Two Aspects in One Sentence. Advances in Computational Intelligence. Springer Berlin Heidelberg. 265–275. ↩
-
Jagarlamudi, J., III, H.D. and Udupa, R. 2012. Incorporating Lexical Priors into Topic Models. EACL, 204–213 ↩
-
Mukherjee, A. and Liu, B. 2012. Aspect Extraction through SemiSupervised Modeling. ACL, 339–348. ↩
-
Zhiyuan Chen, Arjun Mukherjee, Bing Liu, Meichun Hsu, Malu Castellanos, and Riddhiman Ghosh. Leveraging Multi-Domain Prior Knowledge in Topic Models. Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI’13). August 3-9, 2013, Beijing, China. ↩ ↩2
-
David Mimno, Hanna Wallach, Edmund Talley, Miriam Leenders, Andrew McCallum. Optimizing Semantic Coherence in Topic Models. EMNLP (2011). ↩ ↩2
Loading Big Data in R
Although parallel techniques in R has been prevailing, I will only focus on Loading the complete data into RAM in R, that is to say, no Hadoop or similar. What other more I won’t mention in this post is about manipulating and saving big data in R, and parallel computing.
Just start with different implementations:
-
load csv file and using ff package (Rtools)
bigdata <- read.csv.ffdf(file = ”bigdata.csv”, first.rows=5000, colClasses = NA)Notice that ff package should be in Rtools on Windows.
-
using sqldf() from SQLite
this is a method from StackOverflow: using sqldf() to import the data into SQLite as a staging area, and then sucking it from SQLite into R
library(sqldf) f <- file("bigdf.csv") system.time(bigdf <- sqldf("select * from f", dbname = tempfile(), file.format = list(header = T, row.names = F))) -
magic data.table and fread
it includes data.frame, but some of the syntax is different. Luckily, the documentation (and the FAQ) are excellent.
Read csv-files with the fread function instead of read.csv (read.table). It is faster in reading a file in table format and gives you feedback on progress.
Notice that fread() cannot directly read gzipped files and it comes with a big warning sign “not for production use yet”. One trick it uses is to read the first, middle, and last 5 rows to determine column types.
-
optimized read.table()* with **colClasses
This option takes a vector whose length is equal to the number of columns in year table. Specifying this option instead of using the default can make ‘read.table’ run MUCH faster, often twice as fast. In order to use this option, you have to know the of each column in your data frame. - See more at hear.
read.table("test.csv",header=TRUE,sep=",",quote="", stringsAsFactors=FALSE,comment.char="",nrows=n, colClasses=c("integer","integer","numeric", "character","numeric","integer")) -
load a portion using nrows
Also you can read in only a portion of your file, to get a feel of the dataset.
data_first_100 <- read.table("file", header=T, sep="\t", stringsAsFactors=F, nrows=100) -
in summary
Here is a great comparison summary for the method above with their system time. I just copy the summary table below:
## user system elapsed Method ## 24.71 0.15 25.42 read.csv (first time) ## 17.85 0.07 17.98 read.csv (second time) ## 10.20 0.03 10.32 Optimized read.table ## 3.12 0.01 3.22 fread ## 12.49 0.09 12.69 sqldf ## 10.21 0.47 10.73 sqldf on SO ## 10.85 0.10 10.99 ffdf
See more in 11 Tips on How to Handle Big Data in .